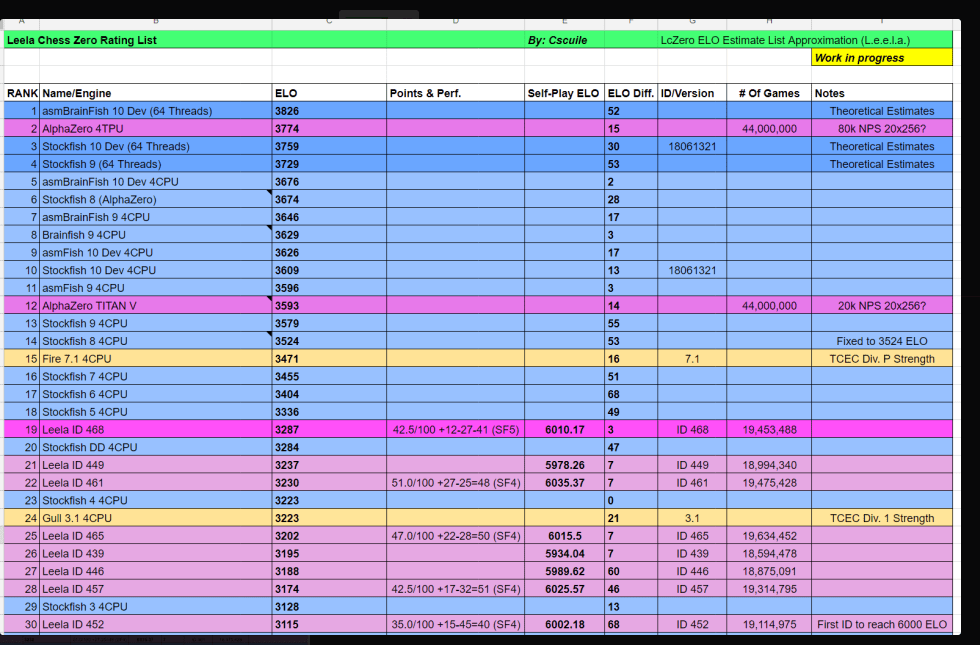
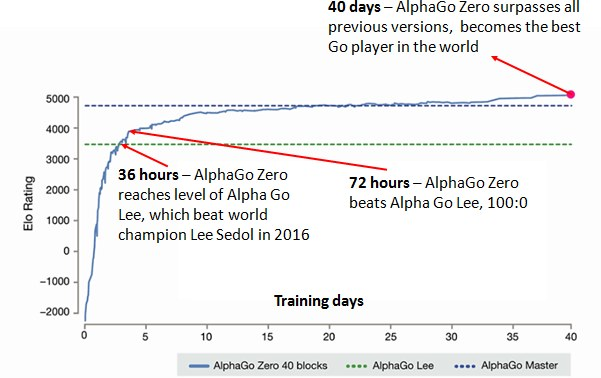
Empirical evaluation of AlphaGo Zero. a Performance of self-play
Por um escritor misterioso
Descrição
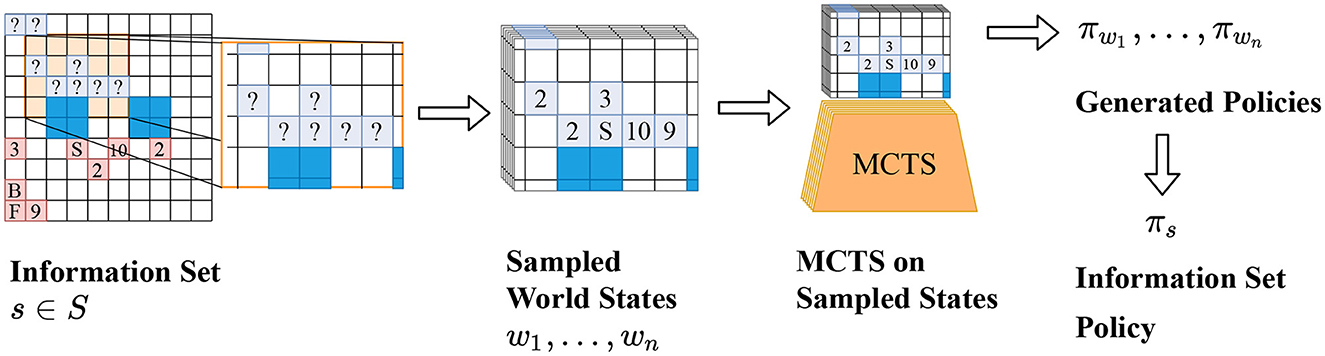
Frontiers AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong

Reinforcement Learning, Fast and Slow: Trends in Cognitive Sciences
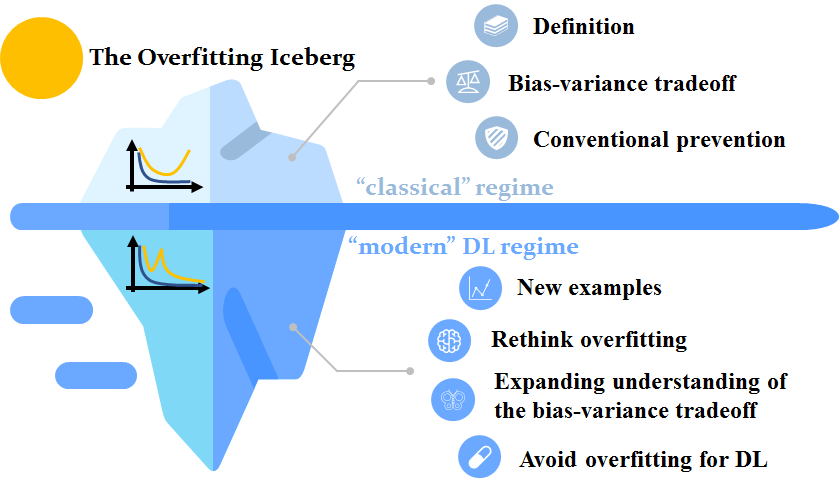
4 – The Overfitting Iceberg – Machine Learning Blog, ML@CMU
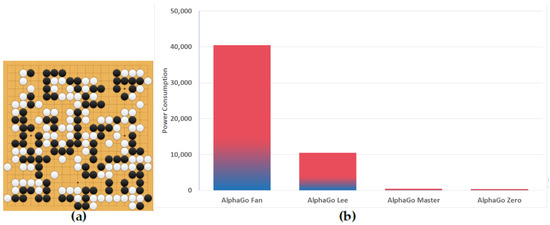
Applied Sciences, Free Full-Text
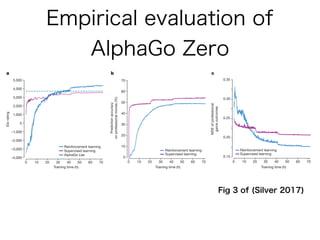
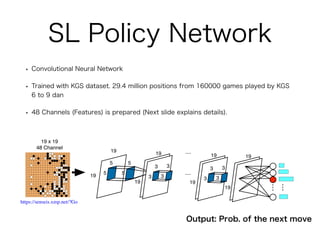
AlphaGo and AlphaGo Zero
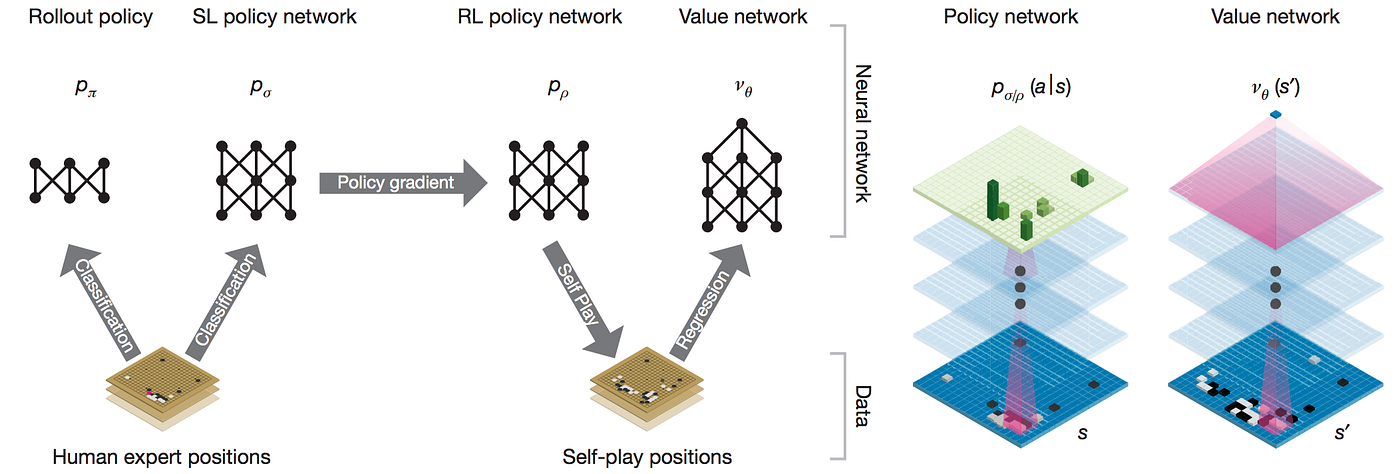
AlphaGo and AlphaGo Zero
AlphaGo, in context. Update Oct 18, 2017: AlphaGo Zero was…, by Andrej Karpathy
How to build your own AlphaZero AI using Python and Keras, by David Foster, Applied Data Science

Interfacing AlphaGo: Embodied play, object agency, and algorithmic drama - Philippe Sormani, 2023

Student of Games: A unified learning algorithm for both perfect and imperfect information games

PDF) Mastering the game of Go without human knowledge

Is AlphaGo Really Such a Big Deal?
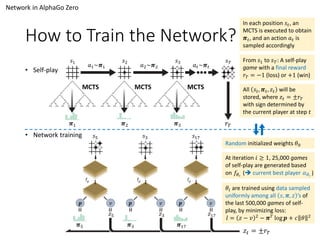
Introduction to Alphago Zero