wiki-reading/data/answer.vocab at master · google-research-datasets/wiki-reading · GitHub
Por um escritor misterioso
Descrição
This repository contains the three WikiReading datasets as used and described in WikiReading: A Novel Large-scale Language Understanding Task over Wikipedia, Hewlett, et al, ACL 2016 (the English WikiReading dataset) and Byte-level Machine Reading across Morphologically Varied Languages, Kenter et al, AAAI-18 (the Turkish and Russian datasets). - wiki-reading/data/answer.vocab at master · google-research-datasets/wiki-reading
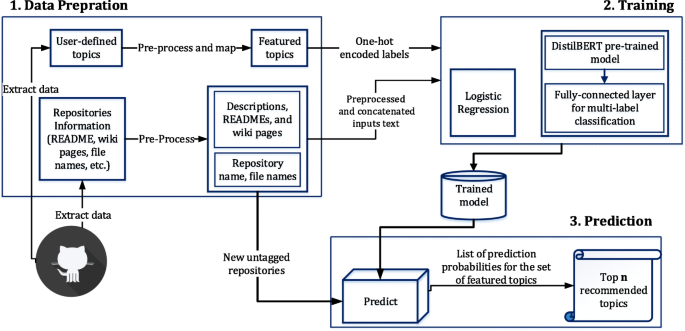
Topic recommendation for software repositories using multi-label classification algorithms
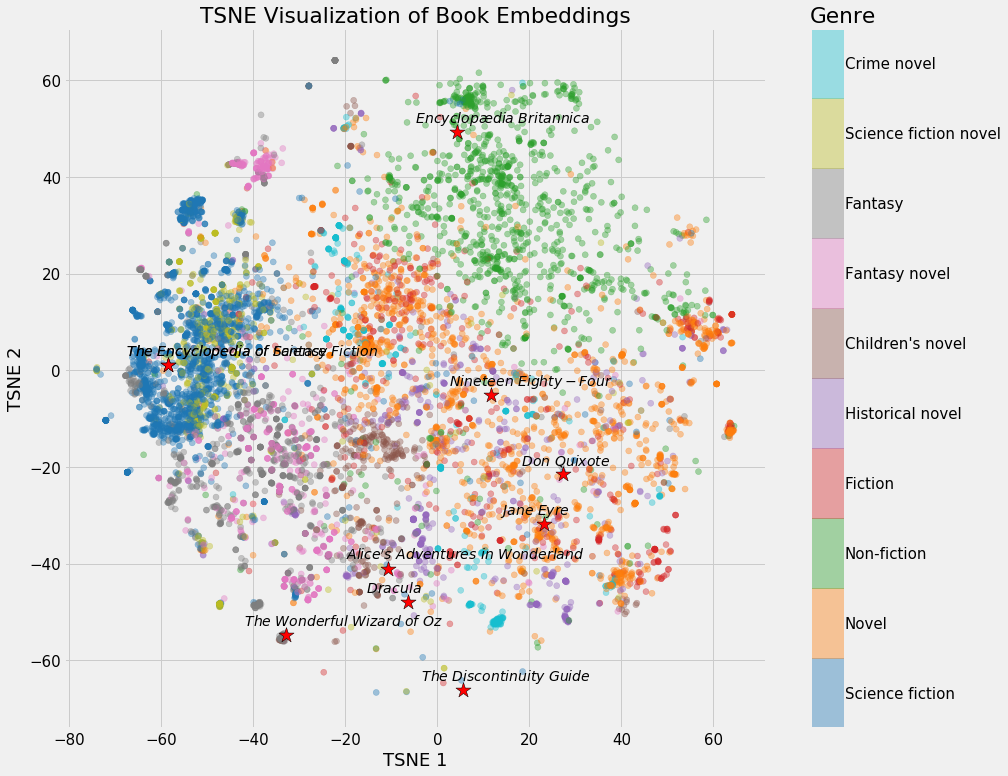
Neural Network Embeddings Explained, by Will Koehrsen

What Is Knowledge Graph Building Knowledge Graph From Text

Quizbowl: The Case for Incremental Question Answering – arXiv Vanity

Geert Lovink, Nathaniel Tkacz, Critical Point of View A Wikipedia Reader by ODA Connexio - Issuu

The Pile: An 800GB Dataset of Diverse Text for Language Modeling – arXiv Vanity
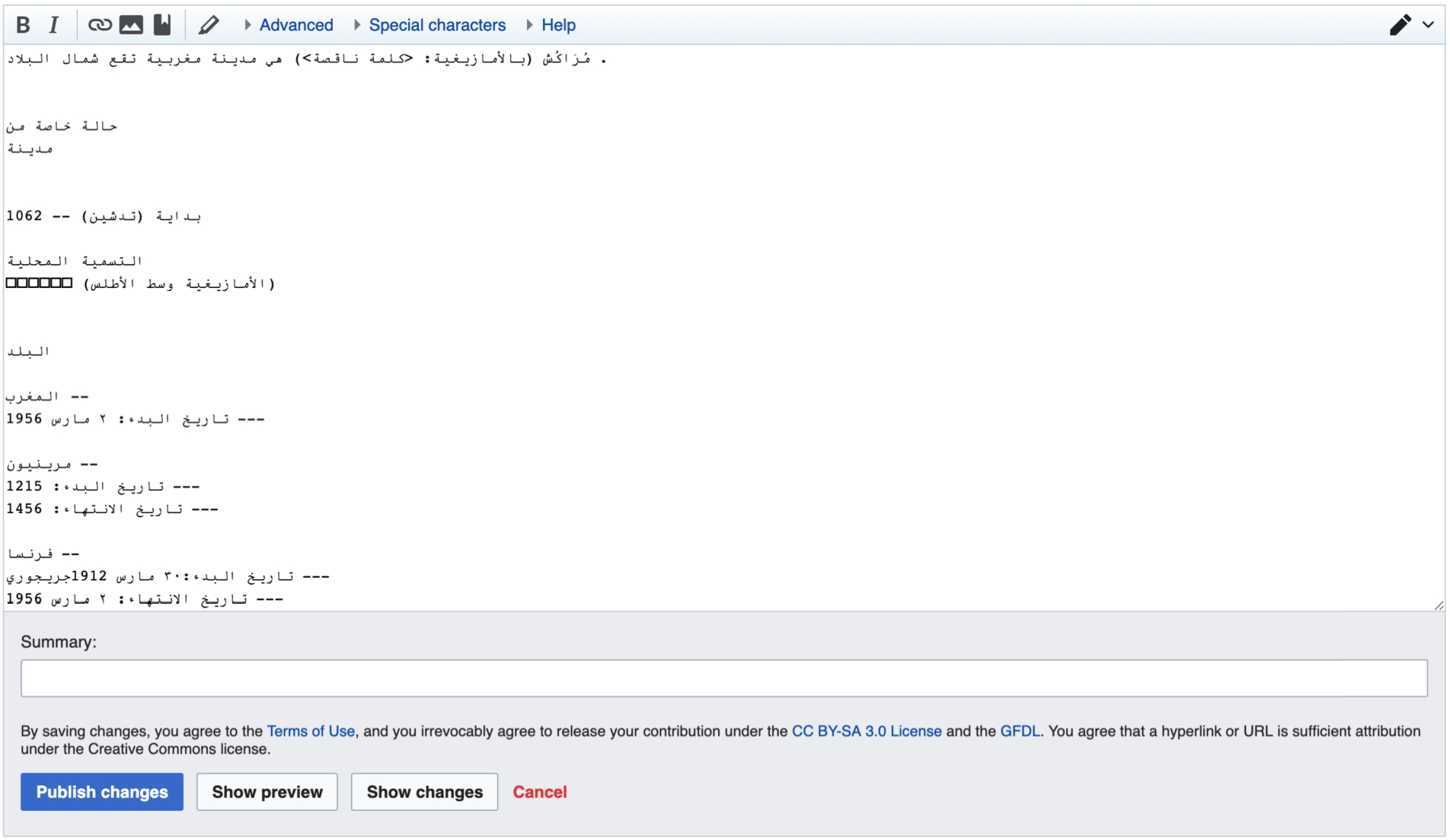
Using natural language generation to bootstrap missing Wikipedia articles: A human-centric perspective - IOS Press
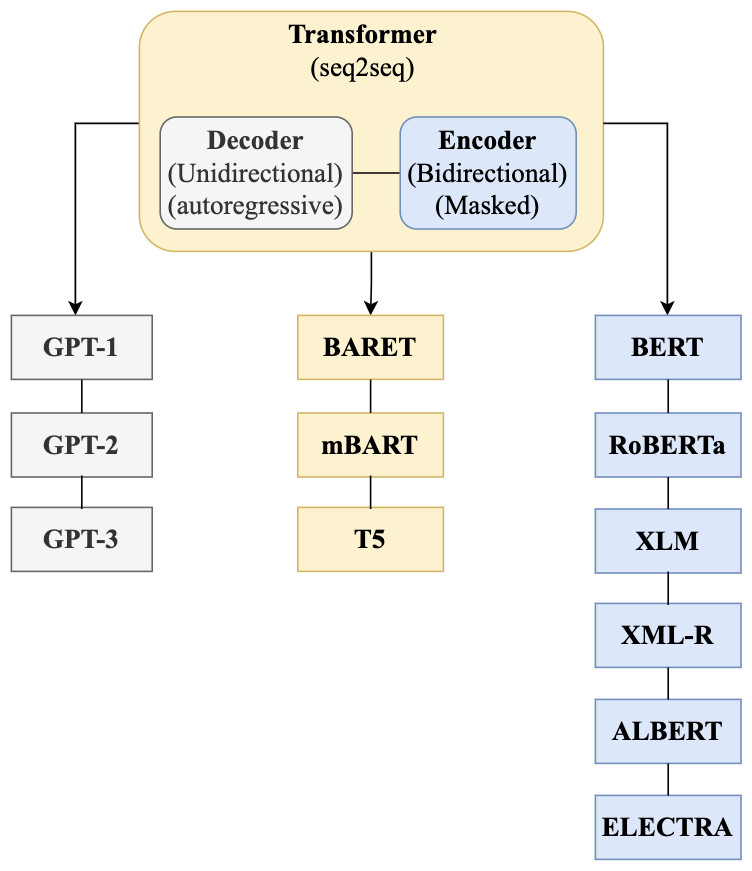
Challenges and opportunities for Arabic question-answering systems: current techniques and future directions [PeerJ]

Usuário Discussão:Ixocactus – Wikipédia, a enciclopédia livre

NLP Tutorial: Question Answering System using BERT + SQuAD on Colab

What Is Knowledge Graph Building Knowledge Graph From Text

Datamining Wikipedia and writing JS with ChatGTP just to swap the colours on university logos…

PDF) Wikidata and knowledge graphs in practice: Using semantic SEO to create discoverable, accessible, machine-readable definitions of the people, places, and services in Libraries and Archives

Reflection on current project state, and a proposal for a metaschema · Issue #23 · jupyterlab/jupyterlab-metadata-service · GitHub







