Evaluation of taxonomic classification and profiling methods for long-read shotgun metagenomic sequencing datasets, BMC Bioinformatics
Por um escritor misterioso
Descrição
Background Long-read shotgun metagenomic sequencing is gaining in popularity and offers many advantages over short-read sequencing. The higher information content in long reads is useful for a variety of metagenomics analyses, including taxonomic classification and profiling. The development of long-read specific tools for taxonomic classification is accelerating, yet there is a lack of information regarding their relative performance. Here, we perform a critical benchmarking study using 11 methods, including five methods designed specifically for long reads. We applied these tools to several mock community datasets generated using Pacific Biosciences (PacBio) HiFi or Oxford Nanopore Technology sequencing, and evaluated their performance based on read utilization, detection metrics, and relative abundance estimates. Results Our results show that long-read classifiers generally performed best. Several short-read classification and profiling methods produced many false positives (particularly at lower abundances), required heavy filtering to achieve acceptable precision (at the cost of reduced recall), and produced inaccurate abundance estimates. By contrast, two long-read methods (BugSeq, MEGAN-LR & DIAMOND) and one generalized method (sourmash) displayed high precision and recall without any filtering required. Furthermore, in the PacBio HiFi datasets these methods detected all species down to the 0.1% abundance level with high precision. Some long-read methods, such as MetaMaps and MMseqs2, required moderate filtering to reduce false positives to resemble the precision and recall of the top-performing methods. We found read quality affected performance for methods relying on protein prediction or exact k-mer matching, and these methods performed better with PacBio HiFi datasets. We also found that long-read datasets with a large proportion of shorter reads (< 2 kb length) resulted in lower precision and worse abundance estimates, relative to length-filtered datasets. Finally, for classification methods, we found that the long-read datasets produced significantly better results than short-read datasets, demonstrating clear advantages for long-read metagenomic sequencing. Conclusions Our critical assessment of available methods provides best-practice recommendations for current research using long reads and establishes a baseline for future benchmarking studies.

Percentage of reads classified correctly or incorrectly in

Evaluation of taxonomic profiling methods for long-read shotgun

PDF) Shotgun metagenomics, from sampling to analysis (2017

Genes, Free Full-Text
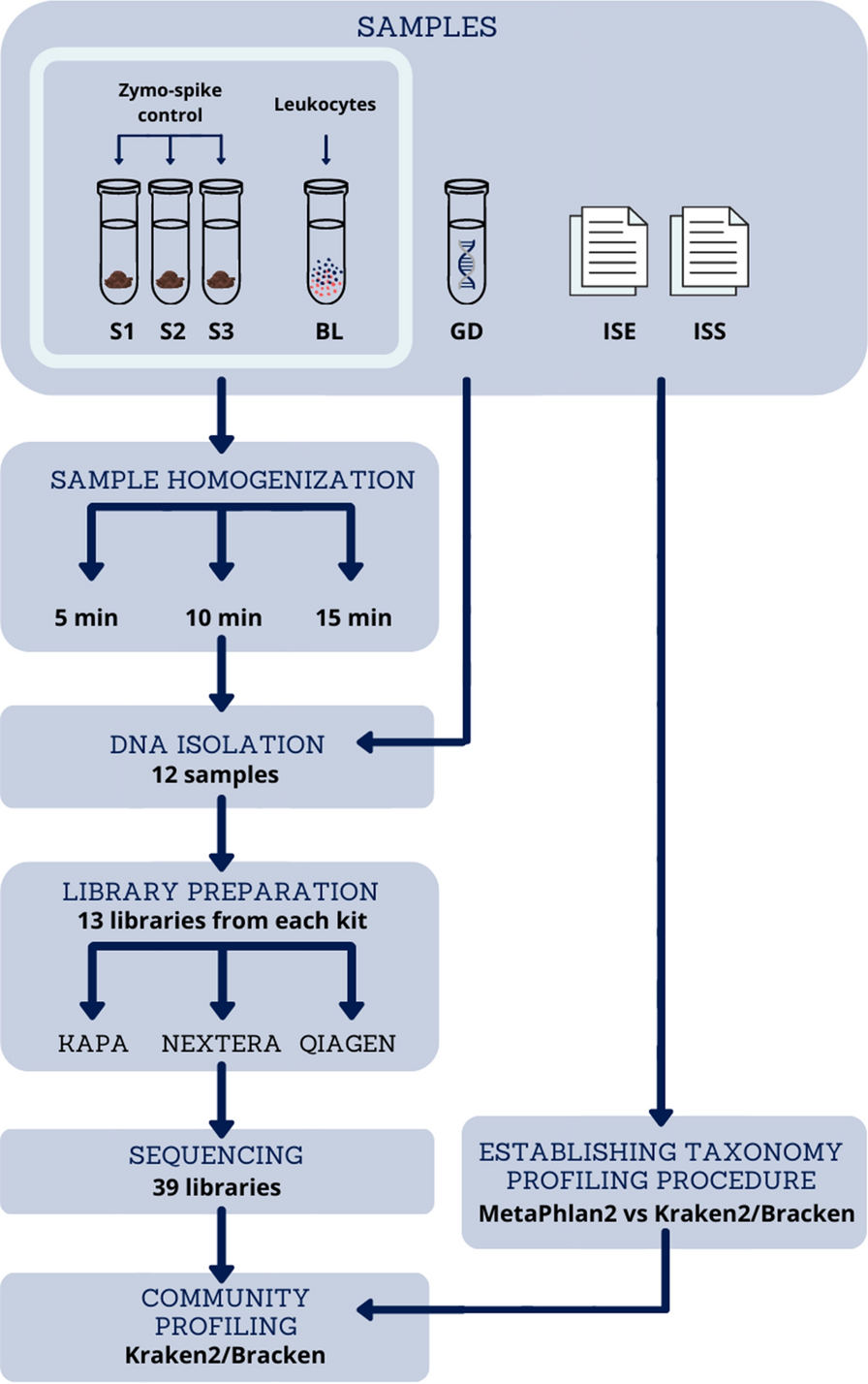
The standardisation of the approach to metagenomic human gut

Recovering metagenome-assembled genomes from shotgun metagenomic
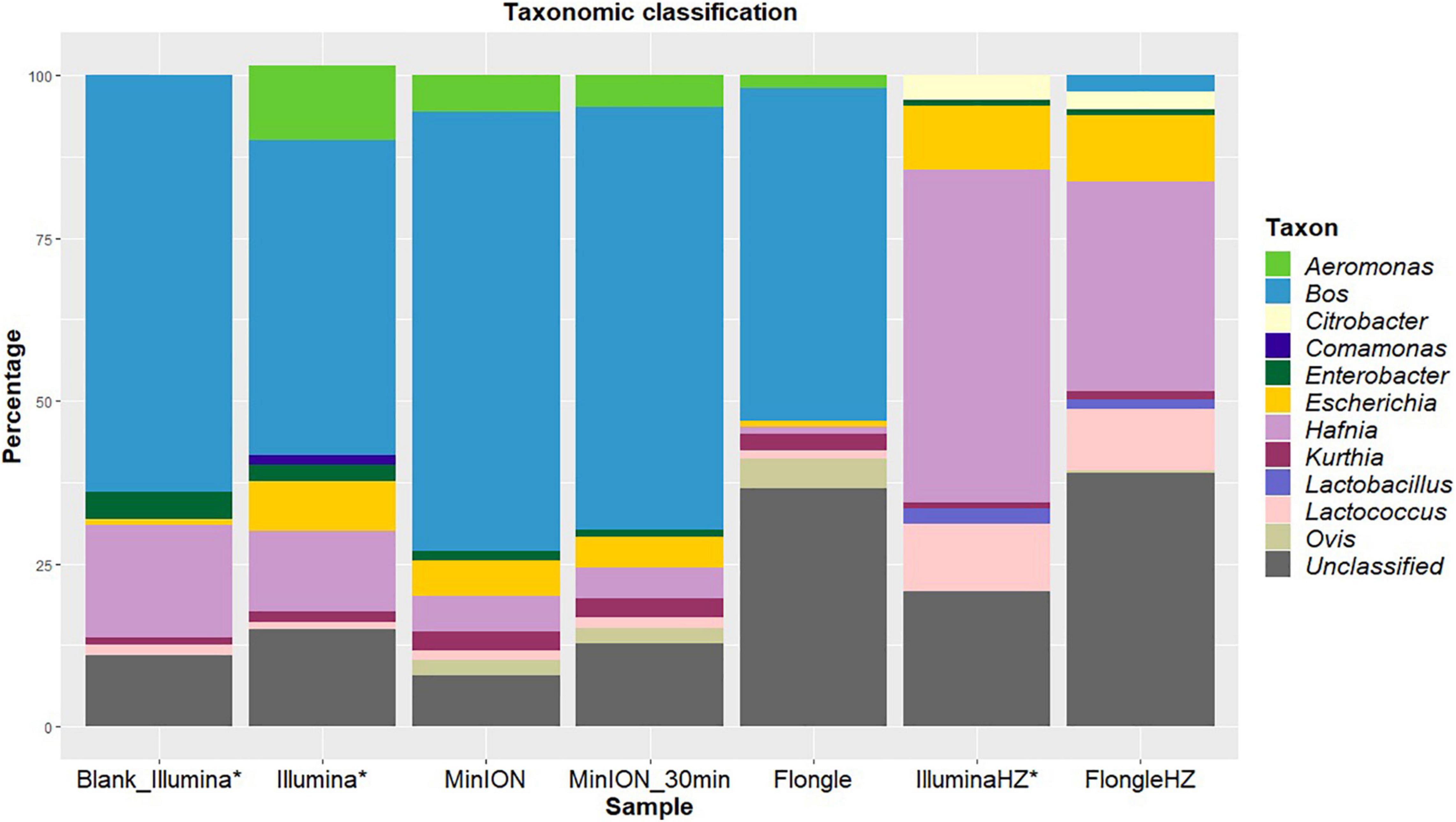
Frontiers Towards Real-Time and Affordable Strain-Level

Performance descriptors plots calculated for methods tested in
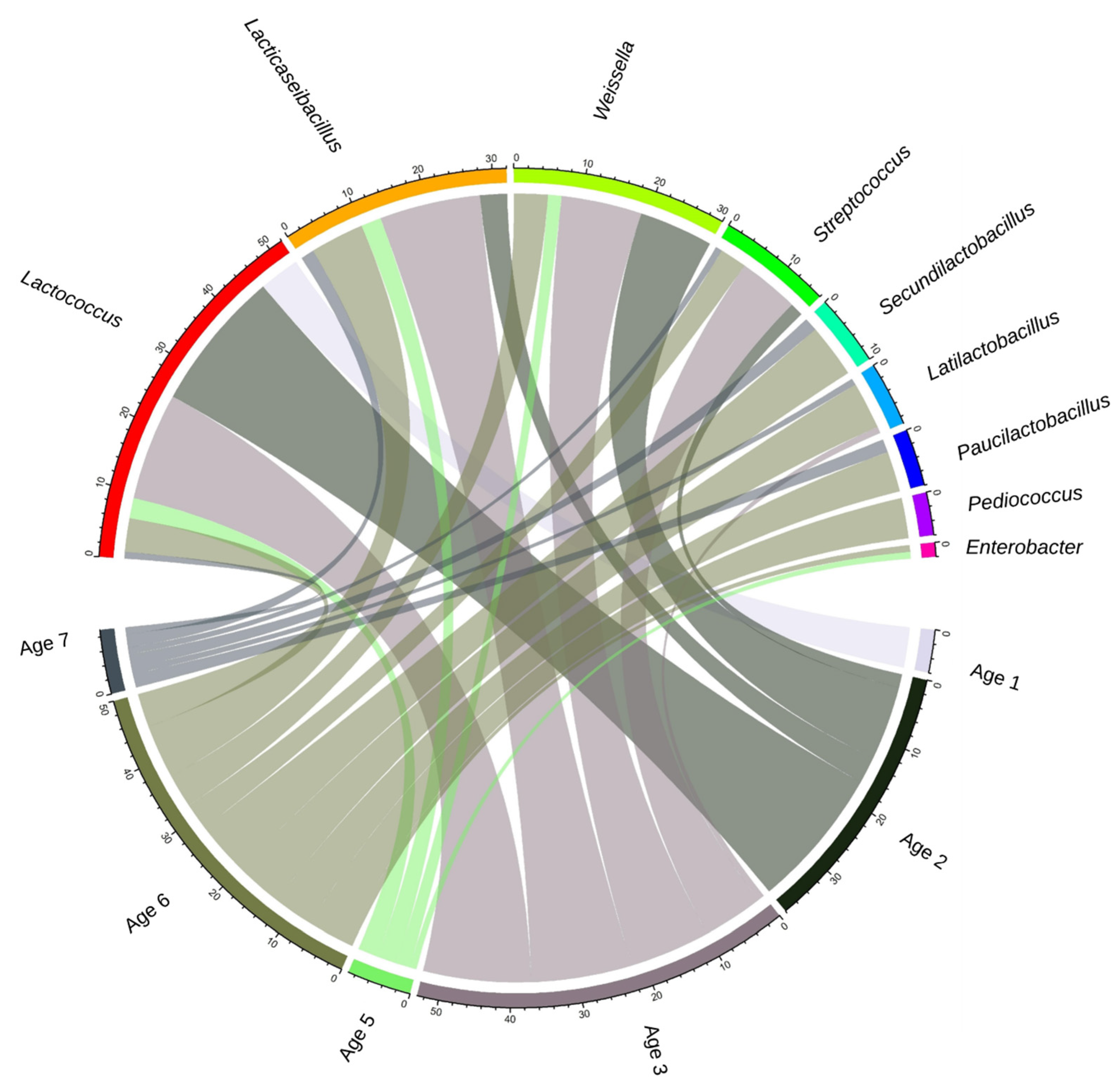
Microorganisms, Free Full-Text
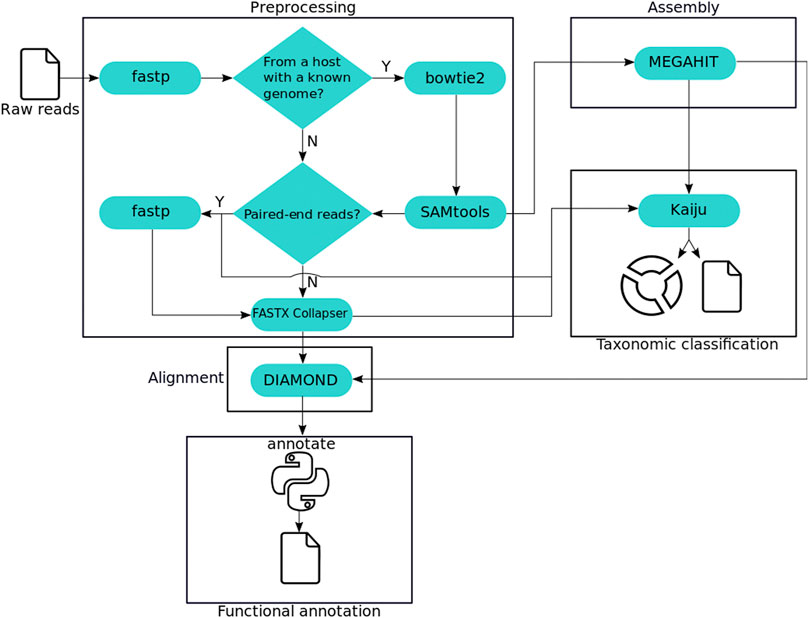
Frontiers MEDUSA: A Pipeline for Sensitive Taxonomic
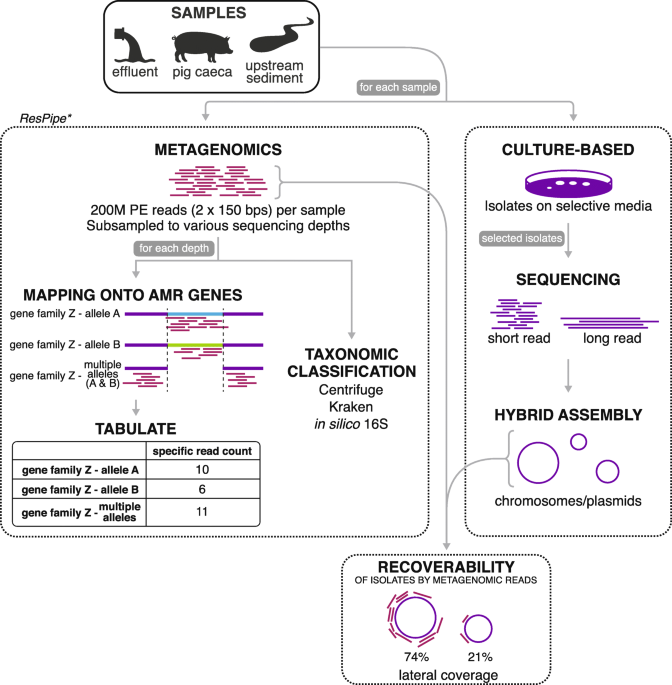
The impact of sequencing depth on the inferred taxonomic

Analysis and Interpretation of metagenomics data: an approach