AlphaGo Zero: Approaching Perfection, by Synced, SyncedReview
Por um escritor misterioso
Descrição
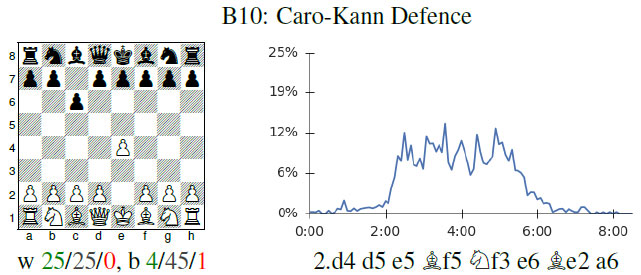
DeepMind recently published a paper in Nature introducing the latest evolution of its AI-powered Go program. “AlphaGo Zero” learns in self-play games, with no human knowledge required. The program…

dThe 3 Tricks That Made AlphaGo Zero Work
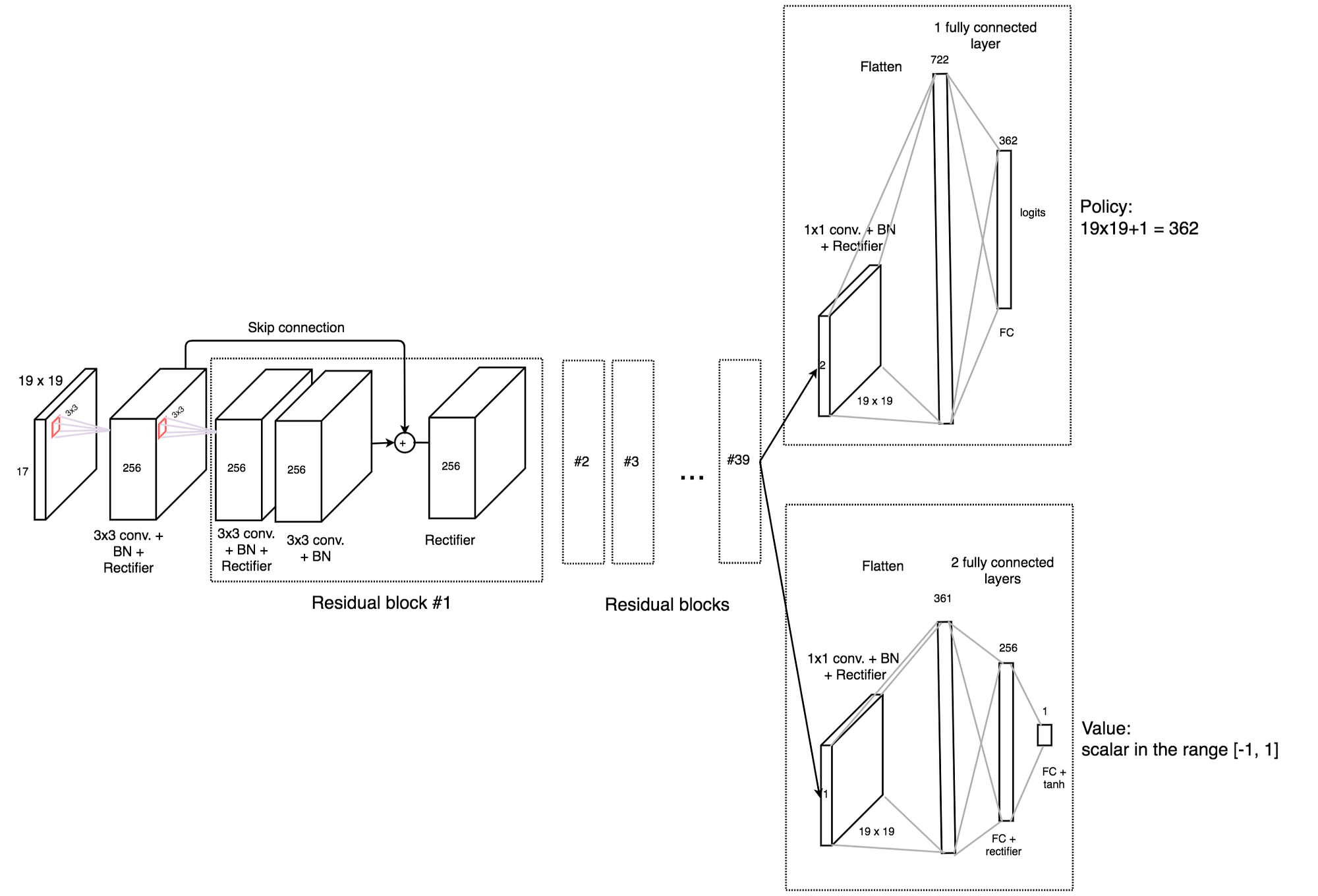
AlphaGo Zero — a game changer. (How it works?), by Jonathan Hui

AI Biweekly: 10 Bits from Oct (Pt 2)
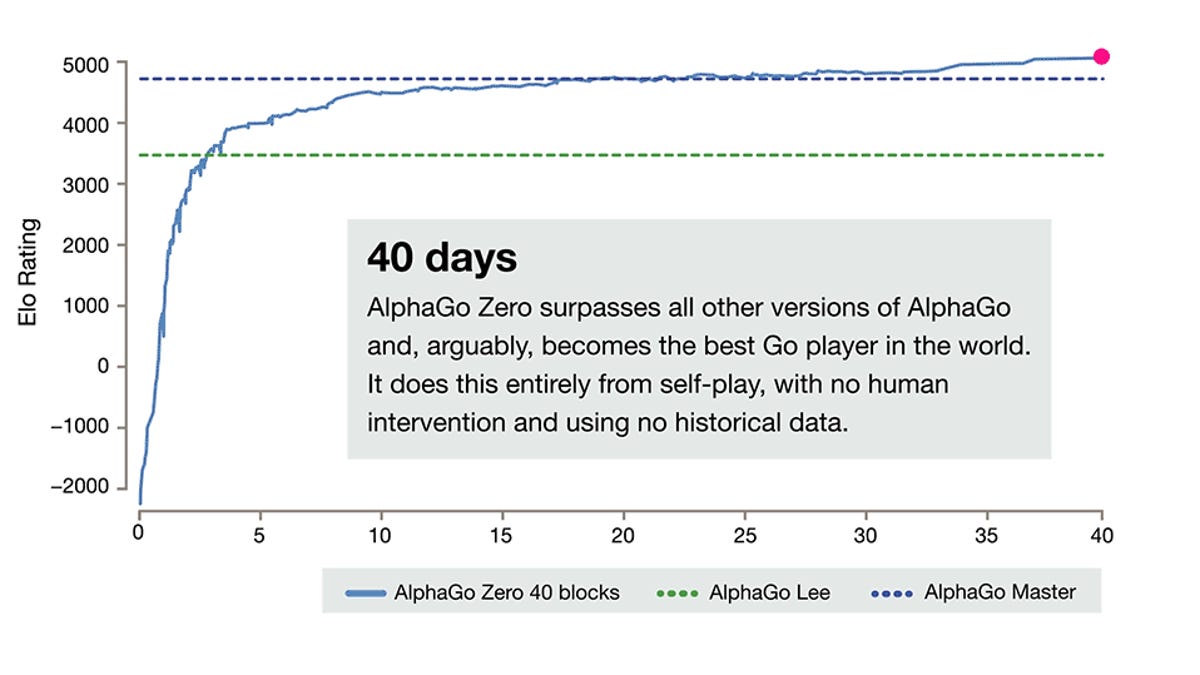
DeepMind AlphaGo Zero learns on its own without meatbag intervention
Data science Archives - Page 2 of 10

DeepMind's AlphaDev Leverages Deep Reinforcement Learning to Discover Faster Sorting Algorithms

This More Powerful Version of AlphaGo Learns On Its Own
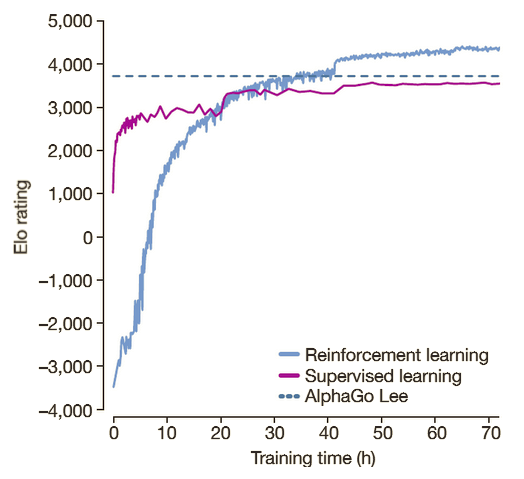
AlphaGo Zero Explained

Chapter 14. AlphaGo Zero: Integrating tree search with reinforcement learning - Deep Learning and the Game of Go
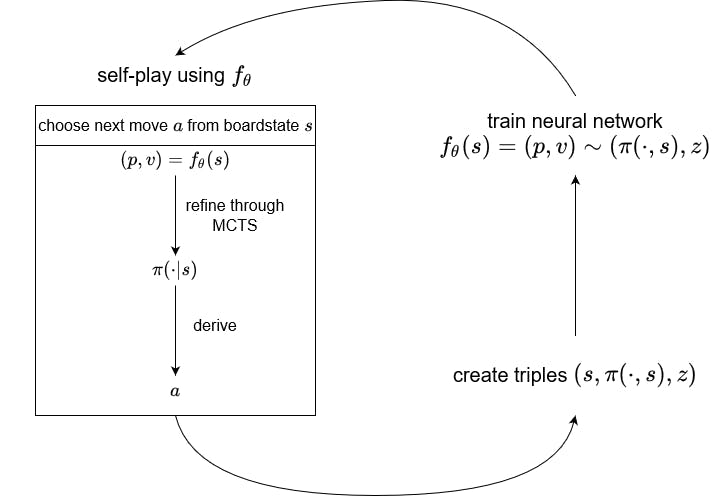
AlphaGo Zero Explained
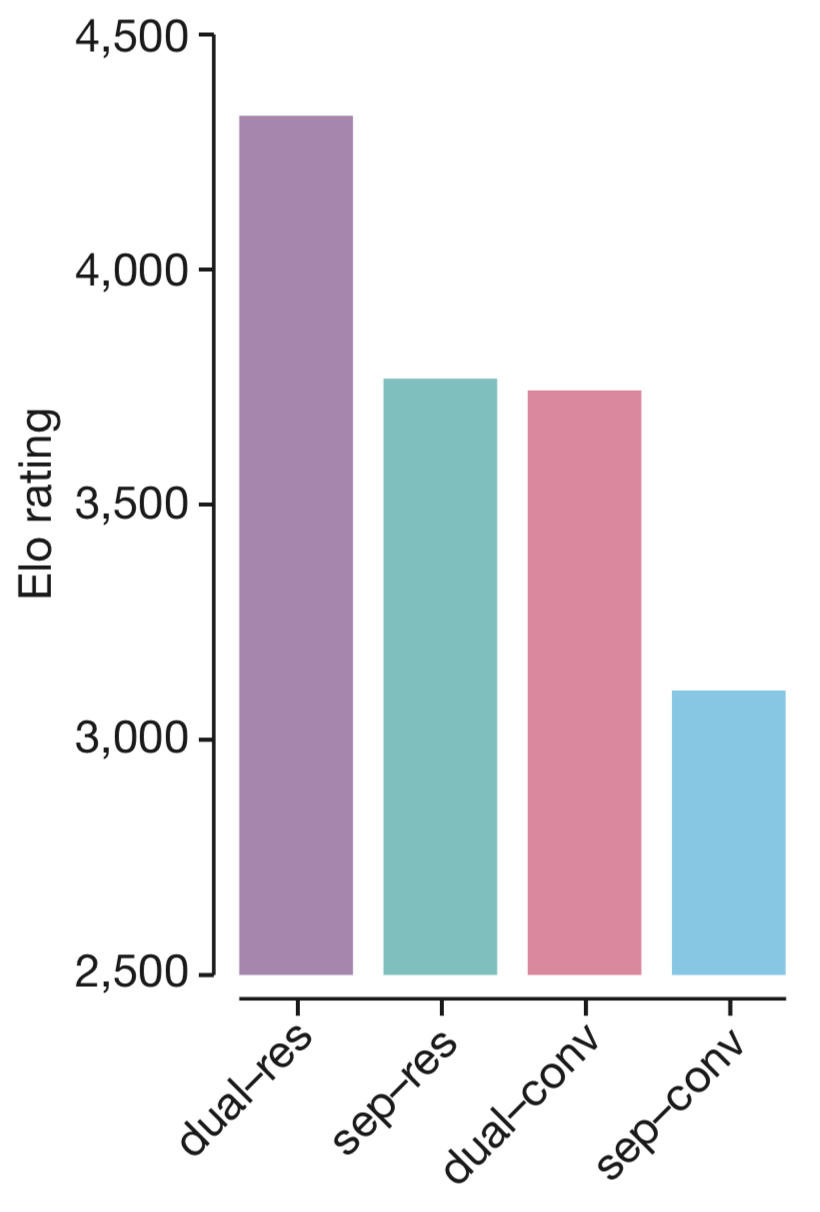
dThe 3 Tricks That Made AlphaGo Zero Work

AlphaGo second paper released: AlphaGo Zero • Life In 19x19

DOC) The Theology of GPT-2: Religion and Artificial Intelligence
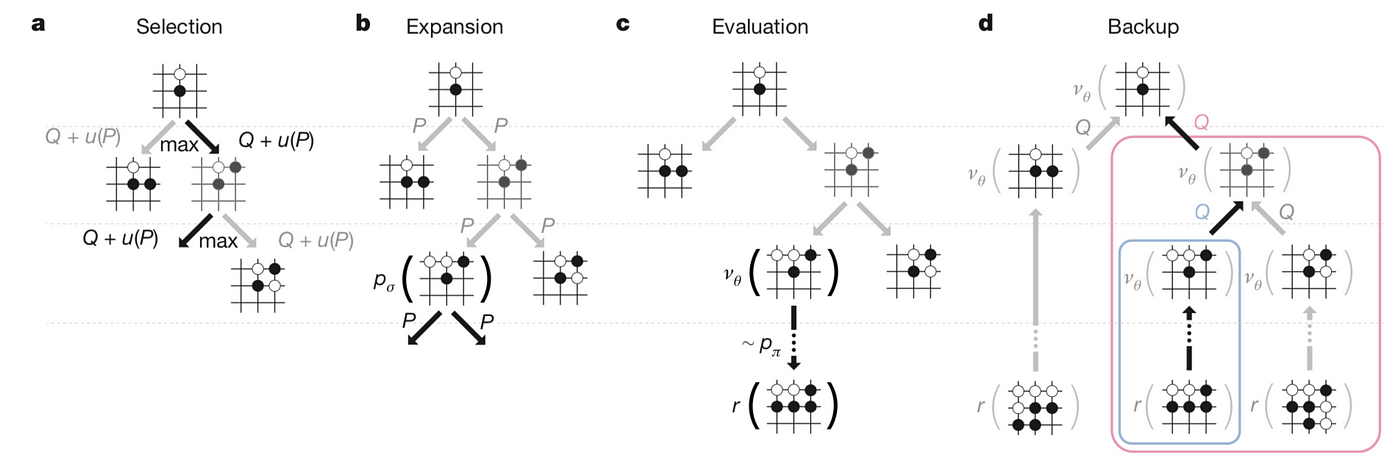
dThe 3 Tricks That Made AlphaGo Zero Work, by Seth Weidman, HackerNoon.com