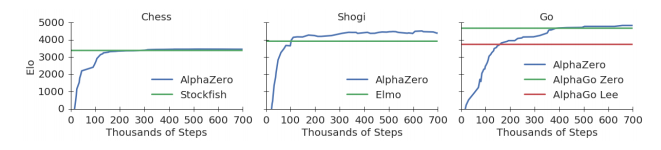
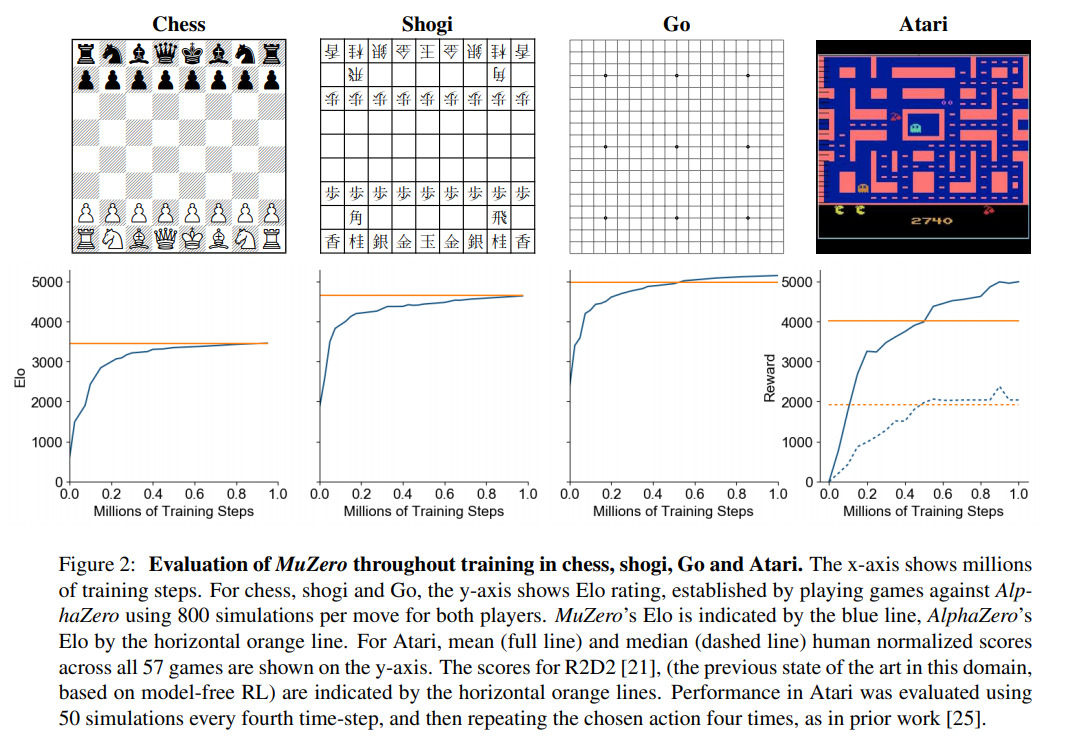
Training AlphaZero for 700,000 steps. Elo ratings were computed
Por um escritor misterioso
Descrição

In chess, Alpha Zero demolished Stockfish in a controlled set of 100 matches. What do you guys think? : r/baduk
How to build your own AlphaZero AI using Python and Keras, by David Foster, Applied Data Science
How many games did Alpha Zero played against itself during its four hours training? - Quora
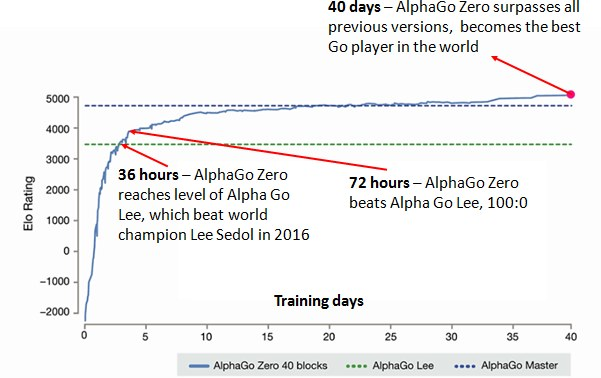
Bagavan Sivam

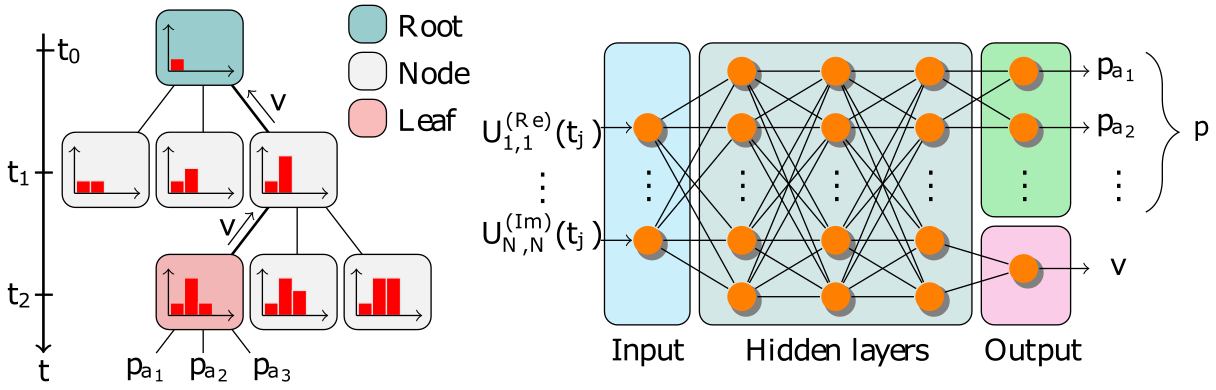
Simple Alpha Zero
A summary of the DeepMind's general reinforcement learning algorithm, AlphaZero, by Umer Hasan

Generally capable agents emerge from open-ended play - Google DeepMind

Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm – arXiv Vanity
AlphaGo/AlphaGoZero/AlphaZero/MuZero: Mastering games using progressively fewer priors

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

AlphaZero paper peer-reviewed is available · Issue #2069 · leela-zero/leela-zero · GitHub

Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm – arXiv Vanity

A summary of the DeepMind's general reinforcement learning algorithm, AlphaZero, by Umer Hasan